
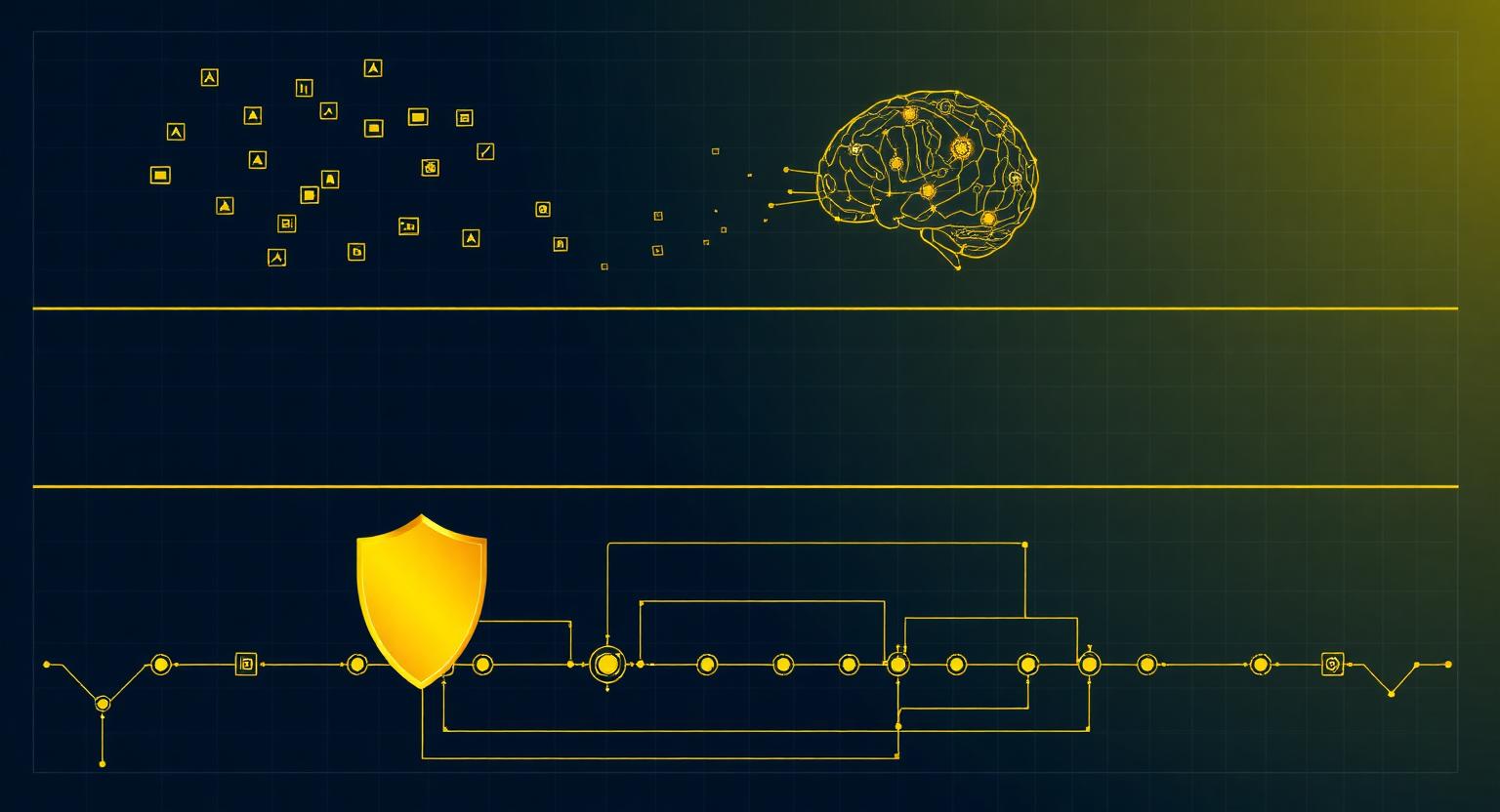
Three states of the same problem — covering every domain of code security (SAST, SCA, secrets, configs, IaC, containers, APIs). Before AI, humans bolted a scanner onto each domain. After AI, teams used AI itself to review the code — which carries three problems: coverage, variance, and token cost. Gadriel runs inside the AI coding environment and fixes it in the background.
State 01 · Before AI — the tool-sprawl era (~2015 – 2022)
Humans wrote the code. Security meant bolting a separate scanner onto each domain — and they all ran at the same place: the CI side (PR / review pipeline), late, after the dev had moved on. Each tool had its own dashboard, its own policy, its own backlog. Findings came back as a wave at CI, so the developer had to context-switch back, fix, re-push, and wait for the pipeline again — lots of back-and-forth, and the code couldn't move downstream until CI cleared. The "shift-left" dream existed, but the tooling stayed bunched at CI.
Domain leaders of the era: SAST — Checkmarx, Fortify, Coverity, SonarQube · SCA — Black Duck, Snyk Open Source, Sonatype Nexus, Mend · Secrets — GitGuardian, TruffleHog · IaC/config — Checkov/Bridgecrew, Terrascan · Containers — Aqua, Twistlock (→ Prisma), Trivy · DAST/API — Veracode, Invicti, Burp.
- Model: one scanner per domain, run late, correlated by humans.
- Gate: PR, CI/CD and security review — friction lives at the end.
- Pain: tool sprawl, alert fatigue, slow remediation, no single view.
State 02 · After AI — let the AI review the code (2023 – today)
Why people reached for AI review: the traditional tools all sat at CI, so every finding meant a round-trip — push, wait for the pipeline, read the wave of results, fix, re-push, wait again. Code couldn't move to the next stage until CI cleared. That back-and-forth is the bottleneck AI promised to skip: have the model review the code at the dev machine, before commit, so nothing waits on CI. The output looks like security — a confident report citing CVE numbers. But because the model itself is doing the analysis, the method carries three problems no prompt removes.
The methods, vendor-neutral: prompt the coding model to audit its own diff · layer on cybersecurity skill packs or secure-coding rulesets · stand up an AI agent that re-scans the repo each pass. Common to all: the model itself is doing the analysis, so it carries the model's cutoff, the model's variance, and the model's per-token cost.
- Coverage: training cutoff = blind to CVEs published after it; the gap is invisible, not flagged.
- Probabilistic: non-deterministic — no guarantee the same code yields the same verdict run to run.
- Token cost: leaning on an AI scanner every commit re-reads the codebase each time — spend scales relentlessly.
- Legacy CD: the old IaC / container / DAST gates still run, but they're built for traditional software — they don't validate AI-system behavior.
State 03 · What Gadriel changes — the scanner that runs itself
Gadriel is the tool the skills were pointing toward — except it runs itself, and it runs across the whole spine through two products. GCA validates the code: on the dev machine it finds and fixes in the background inside the coding environment you already use (Claude Code, Cursor, Windsurf, Aider); at commit it's a blocking gate, so bad code never enters history; in CI it enforces the same eight controls in the build. Then GRA takes over at CD — validating the running AI system (agents, RAG, LLM, MCP, A2A) before deploy, the exact thing the legacy CD tools (IaC, container, DAST) were never built to see.
And it fixes State 02's three problems at the root: it validates every line against a live OSV feed (270,336 advisories, 11 ecosystems) so there is no training cutoff; it's deterministic and reproducible — same input, same output, audit-defensible; and it's a real scanner, not the model re-reading the repo each run, so token cost stays flat. 100% local, emits SBOMs (SPDX + CycloneDX), across all eight pillars — not security alone.
- GCA · code: validates code at dev, commit (blocking) and CI — same eight controls, before bad code enters history.
- GRA · CD: at deploy, validates the running AI system — agents, RAG, LLM, MCP, A2A — which legacy CD tools can't.
- Full spine: covered dev → CD, where traditional tools only reached CI and AI review only the dev machine.
- Why it holds: live OSV feed (no cutoff) · deterministic (reproducible) · real scanner (flat token cost).
Validate what AI writes, what AI does, and what AI costs.
Vendor names and market data drawn from 2025–2026 AppSec / AI-code-security sources; used for illustrative positioning.